First commit
parents
No related branches found
No related tags found
Showing
- .gitignore 9 additions, 0 deletions.gitignore
- LICENSE 21 additions, 0 deletionsLICENSE
- archetypes/default.md 6 additions, 0 deletionsarchetypes/default.md
- config.toml 56 additions, 0 deletionsconfig.toml
- content/_index.md 4 additions, 0 deletionscontent/_index.md
- content/documentation/HTMLevator.md 370 additions, 0 deletionscontent/documentation/HTMLevator.md
- content/documentation/_index.md 4 additions, 0 deletionscontent/documentation/_index.md
- content/documentation/editoria-typescript.md 113 additions, 0 deletionscontent/documentation/editoria-typescript.md
- content/documentation/images/html-768x251.png 0 additions, 0 deletionscontent/documentation/images/html-768x251.png
- content/documentation/images/math_docx.png 0 additions, 0 deletionscontent/documentation/images/math_docx.png
- content/documentation/images/math_ff.png 0 additions, 0 deletionscontent/documentation/images/math_ff.png
- content/documentation/images/table-demo.html 61 additions, 0 deletionscontent/documentation/images/table-demo.html
- content/documentation/images/table_html.png 0 additions, 0 deletionscontent/documentation/images/table_html.png
- content/documentation/images/table_word.png 0 additions, 0 deletionscontent/documentation/images/table_word.png
- content/documentation/images/wax_notes-768x472.png 0 additions, 0 deletionscontent/documentation/images/wax_notes-768x472.png
- content/documentation/images/word_xml-768x1504.png 0 additions, 0 deletionscontent/documentation/images/word_xml-768x1504.png
- content/documentation/overview.md 50 additions, 0 deletionscontent/documentation/overview.md
- content/documentation/xsweet-core.md 346 additions, 0 deletionscontent/documentation/xsweet-core.md
- content/involved/_index.md 4 additions, 0 deletionscontent/involved/_index.md
- content/involved/how-to.md 33 additions, 0 deletionscontent/involved/how-to.md
.gitignore
0 → 100644
LICENSE
0 → 100755
archetypes/default.md
0 → 100644
config.toml
0 → 100644
content/_index.md
0 → 100644
content/documentation/HTMLevator.md
0 → 100644
content/documentation/_index.md
0 → 100644
content/documentation/editoria-typescript.md
0 → 100644
{kind=link}

185 KiB
content/documentation/images/math_docx.png
0 → 100644
{kind=link}

35.6 KiB
content/documentation/images/math_ff.png
0 → 100644
{kind=link}

37.5 KiB
content/documentation/images/table-demo.html
0 → 100644
content/documentation/images/table_html.png
0 → 100644
{kind=link}

39.6 KiB
content/documentation/images/table_word.png
0 → 100644
{kind=link}

37.6 KiB
{kind=link}
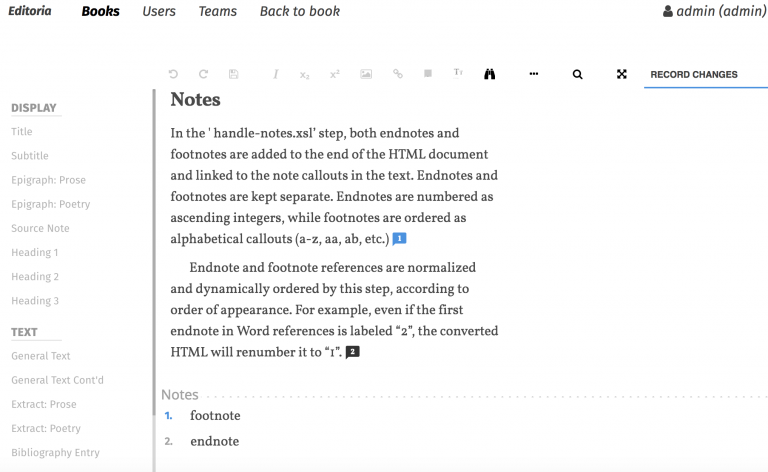
142 KiB
{kind=link}
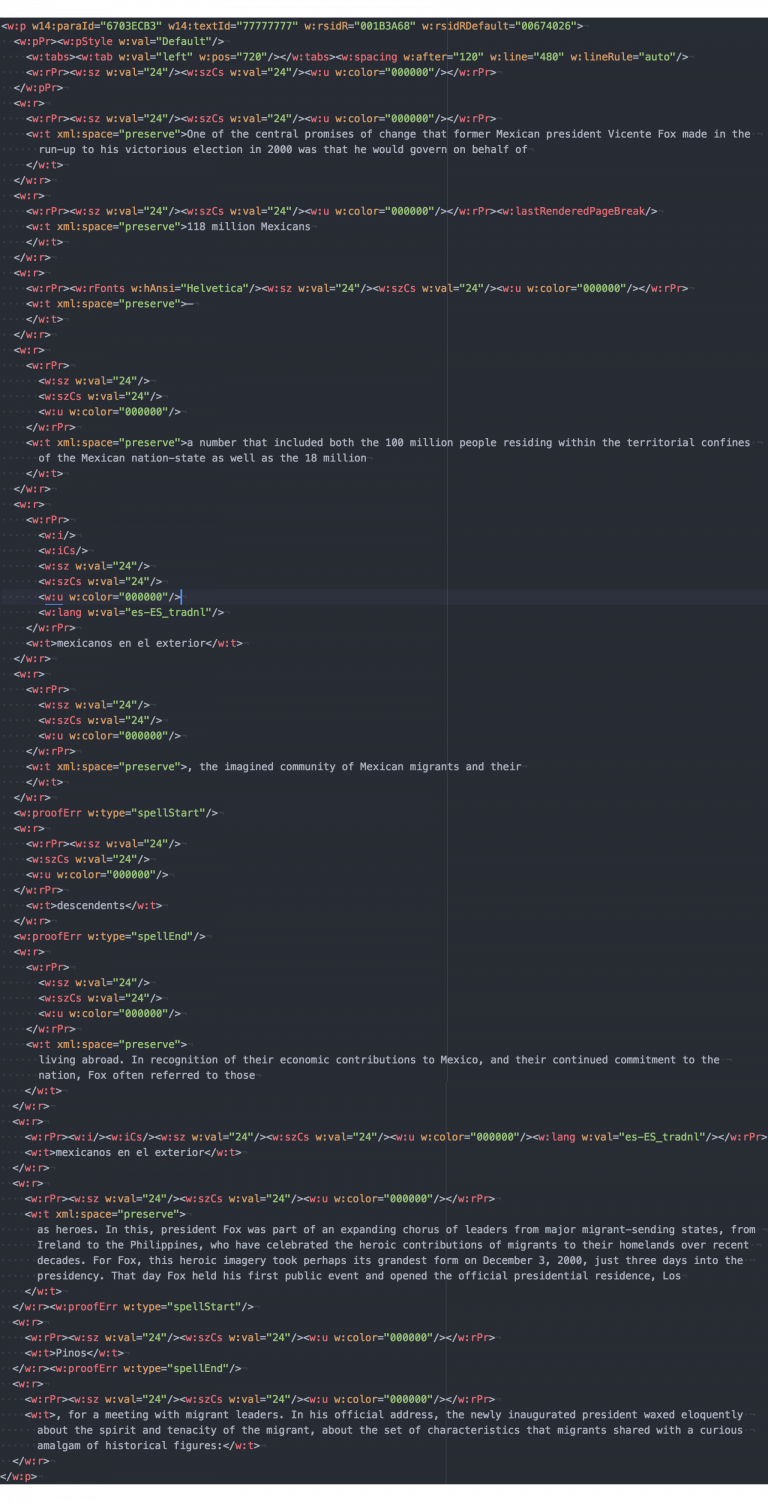
459 KiB
content/documentation/overview.md
0 → 100644
content/documentation/xsweet-core.md
0 → 100644
content/involved/_index.md
0 → 100644
content/involved/how-to.md
0 → 100644